
August 5, 2024
Data Annotation For Genai: Inside Sigma's Upskilling Approach
Prejudice And Variation In Artificial Intelligence Typical ones include Mean Squared Mistake (MSE) for regression and cross-entropy for category. These features form version efficiency and guide optimization methods like gradient descent, resulting in better predictions. Explainability efforts to make a black-box model's decisions reasonable by people ( Burkart & Huber, 2021). Transparent descriptions are crucial to attaining customer trust of and fulfillment with ML systems ( Lim et al., 2009; Kizilcec, 2016; Zhou et al., 2019).The Mystery of ADASYN is Revealed - Towards Data Science
The Mystery of ADASYN is Revealed.
Posted: Tue, 14 Jun 2022 07:00:00 GMT [source]
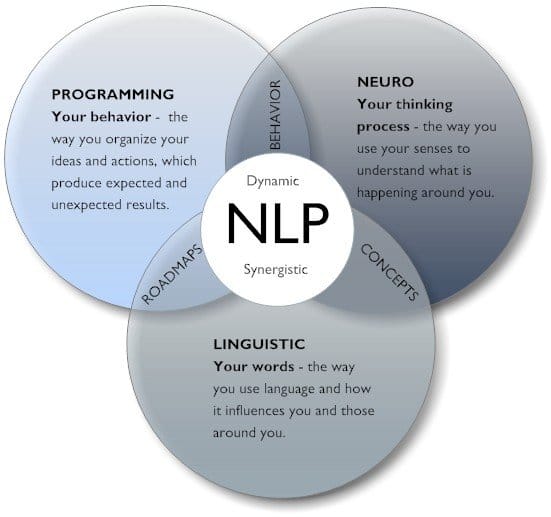

Unexposed Semantic Evaluation And Latent Dirichlet Appropriation
- Scientist found that deep networks find out ordered feature depictions (easy functions like edges at the most affordable layers with slowly even more intricate attributes at greater layers).
- ( 2 ) Joint impact extends influence to think about numerous examination instances collectively ( Jia et al., 2022; Chen et al., 2022).
- A confusion matrix is an efficiency assessment device in artificial intelligence, representing the accuracy of a category design.
- For that reason, impact analysis can be used to detect these very remembered training circumstances.
- This approach makes sure specific fairness, and there are other fairness ideas similar to counterfactuals, such as the team fairness assumption and the counterfactual fairness presumption.
Different Mixes Of Bias-variance
They then swap the labels in such a way that a favorable outcome for the deprived group is most likely and re-train. This is a heuristic technique that empirically enhances justness at the expense of precision. However, this may lead to various false favorable and true positive prices if the true outcome $y$ does really differ with the secured characteristic $p$. Even if the amount of data is sufficient to represent each team, training information may show existing prejudices (e.g., that female employees are paid less), and this is difficult to get rid of. For that reason, there is often a trade-off between various concepts of fairness that the model should thoroughly take into consideration for decision-making systems. A couple of articles talk about the challenges of specifying and accomplishing variously specified justness in machine learning versions and suggest numerous services to attend to these difficulties [98, 99, 105] Predisposition in the data describes the existence of systematic errors or inaccuracies that deplete the fairness of a design if we make use of these prejudiced data to train a design. Prejudice can possibly exist in all information types as prejudice can emerge from a checklist of aspects [95] To make certain fairness, the regressive design should have small differences in preliminary wage offerings for candidates with the exact same certifications yet different age ranges, races, or genders. Hence, developing techniques that make up nuanced differences amongst groups as opposed to focusing exclusively on binary end results can be a significant payment in this field [147] Finally, With the goal of exact image category models, Yang et al. introduce a two-step strategy to filtering and balancing the distribution of photos in the preferred Imagenet dataset of people Fast Phobia Cure from different subgroups [91] In the filtering action, they get rid of inappropriate pictures that reinforce damaging stereotypes or show people in degrading ways. Today's uncurated, internet-derived datasets commonly consist of various strange circumstances ( Pleiss et al., 2020). Strange training circumstances additionally occur as a result of human or mathematical labeling errors-- even on widely known, highly-curated datasets ( Ekambaram et al., 2017). Malicious foes can insert anomalous poison instances right into the training information with the objective of controling details design forecasts ( Biggio et al., 2012; Chen et al., 2017; Shafahi et al., 2018; Hammoudeh & Lowd, 2023). Much better group impact estimators can be instantly used in numerous domains such as poisoning assaults, coreset option, and model explainability. SV has actually likewise been put on research other types of impact beyond training established subscription. For instance, Neuron Shapley uses SV to identify the version nerve cells that are most crucial for an offered forecast ( Ghorbani & Zou, 2020). Lundberg & Lee's (2017) SHAP is an extremely popular tool that uses SV to gauge feature relevance. For a comprehensive study of Shapley value applications past training data affect, see the job of Sundararajan & Najmi (2020) and a much more current upgrade by Rozemberczki et al. (2022 ). ( 1 ) Remember that pointwise impact quantifies the result of a solitary training circumstances on a single examination prediction. Let's code a confusion matrix with the Scikit-learn (sklearn) library in Python. This suggests that we don't know what our classifier is making the most of-- accuracy or recall. So, we utilize it in combination with other evaluation metrics, giving us a complete photo of the outcome. Let's state you want to anticipate the number of people are contaminated with a contagious virus in times before they show the signs and isolate them from the healthy and balanced population (calling any kind of bells, yet?). Information sharing does not relate to this article as no datasets were produced or assessed throughout the existing research study. The final score will be based on the entire examination set, yet let's have a look at ball games on the private sets to obtain a sense of the irregularity in the statistics between sets. We'll likewise develop an iterator for our dataset using the lantern DataLoader class. This assists in saving on memory throughout training since, unlike a for loop, with an iterator the entire dataset does not need to be loaded right into memory.Social Links